Results
Project Outcome
In overall the project was completed in three stages.
INPUT DATA
User must upload an image consisting of valid playing cards excluding the Joker. Ideally for the engine to work the best the user must upload an image containing of 3 to 5 community cards (visible on the deck) and the 2 cards from the hand of the user.
FIRST STAGE
The first stage involves the usage of image classification, classifying an input user image into a valid playing card or not a card. If its categorized as a valid playing card, it is exposed to the next module: the Detector.
SECOND STAGE
The Detector detects which playing cards are present within the input image with confidence scores.
THIRD STAGE
The final stage infers the best poker hand possible with any combination of the seven cards detected within the image.

Stage 1 | Image Classification | CNNs
1.1. Overview
To start simple: image classification marks the initial stage. The goal of this stage was to develop an image classification model capable of recognizing playing cards using Convolutional Neural Networks (CNNs). The dataset consists of images depicting various playing cards, each labeled with its corresponding card type. The dataset was divided into three sets: training, validation, and test sets.
The labels were derived from the file names, where each label represented a playing card, such as '10_C' for 10 of clubs and 'A_S' for Ace of Spades.
To facilitate model training, these labels were integer-encoded using simple label encoder, and thus the final label count was 52 (0, 1, 2, ...., 51).

1.2. Model Architecture and Training
The input dataset comprised of images of playing cards with corresponding labeled card names. The dataset was split into training and testing sets to train the model accurately. The CNN (Convolutional Neural Network) model was implemented using the Keras Sequential API. The architecture consisted of multiple convolutional layers (Conv2D) followed by max-pooling layers to extract hierarchical features. Dropout layers were introduced to prevent overfitting by randomly deactivating a fraction of neurons during training.
The last layers included fully connected (dense) layers for classification, with the output layer having 52 units, representing the number of classes (playing cards). So every input image was categorized into one of the playing cards label.
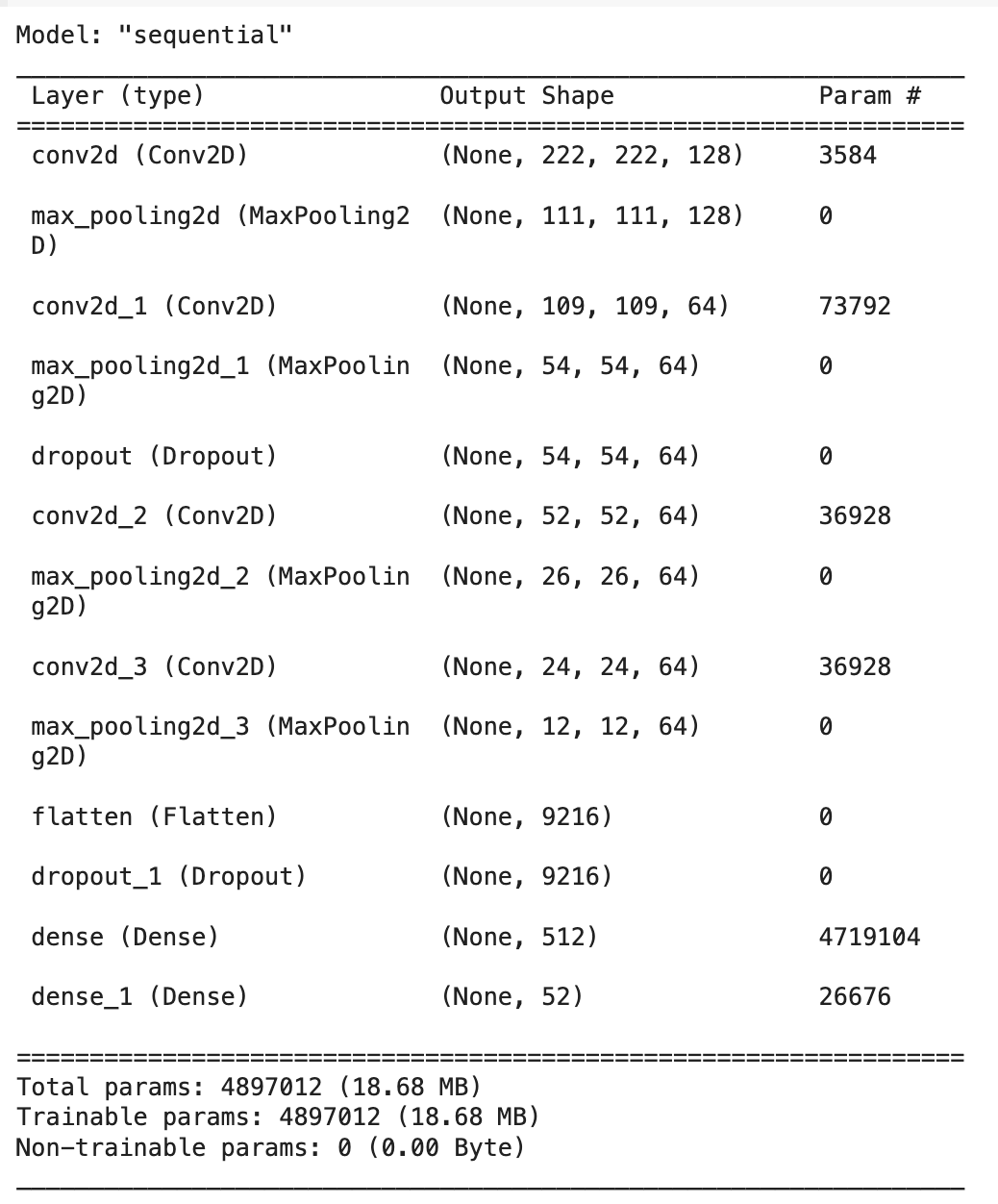

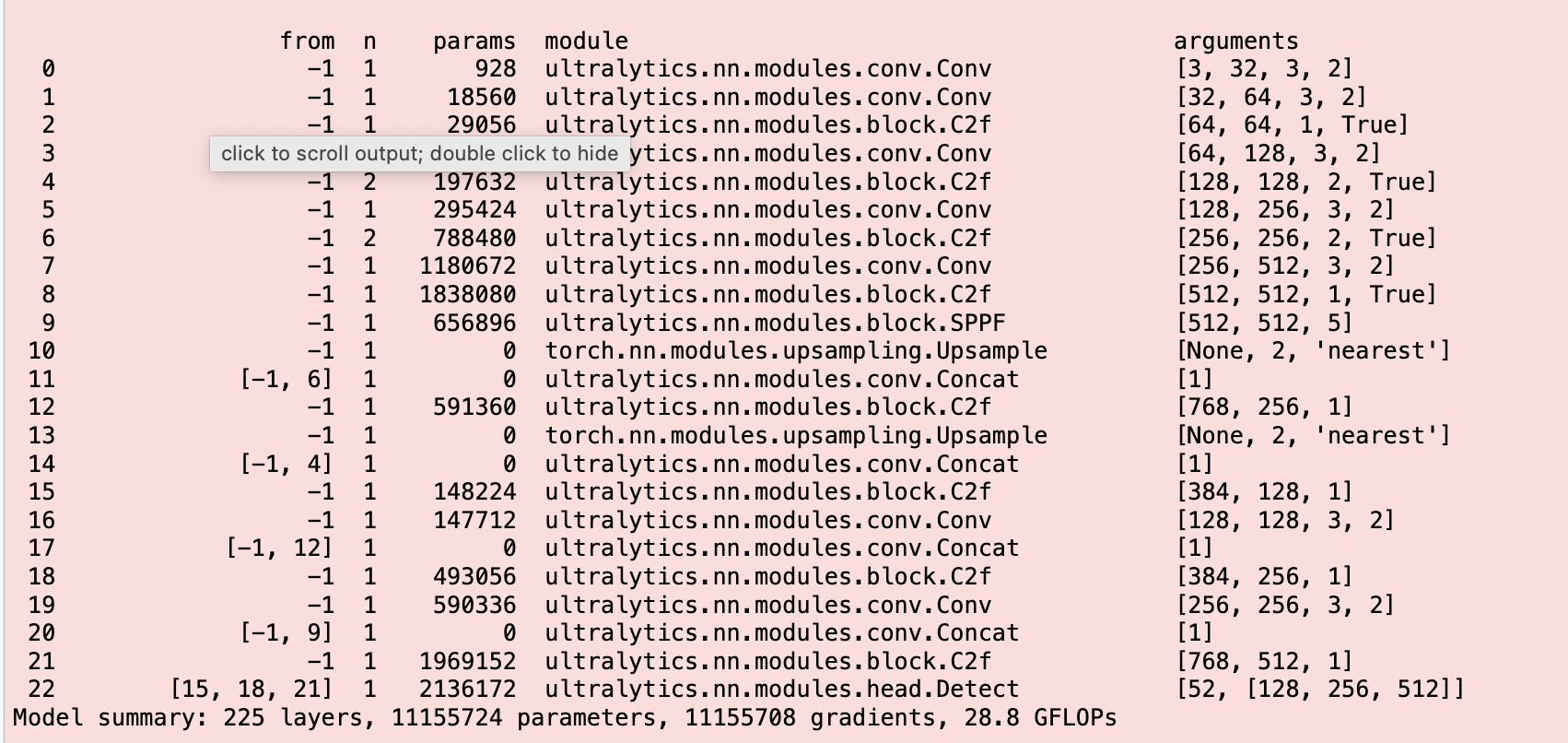
Model Architecture
CNN Sequential model was implemented using the Keras library:
The first convolutional layer (Conv2D) with 128 filters and a kernel size of 3x3.
Max pooling layer (MaxPooling2D) with a pool size of 2x2.
The second convolutional layer (Conv2D) with 64 filters and a kernel size of 3x3.
Another max pooling layer with a pool size of 2x2.
Dropout layer to prevent overfitting.
The third convolutional layer (Conv2D) with 64 filters and a kernel size of 3x3.
A max pooling layer with a pool size of 2x2.
The fourth convolutional layer (Conv2D) with 64 filters and a kernel size of 3x3.
Another max pooling layer with a pool size of 2x2.
Flatten layer to transform the output into a one-dimensional array.
Dropout layer for regularization.
A fully connected dense layer with 512 neurons.
Output dense layer with 52 neurons, representing the number of unique playing cards.
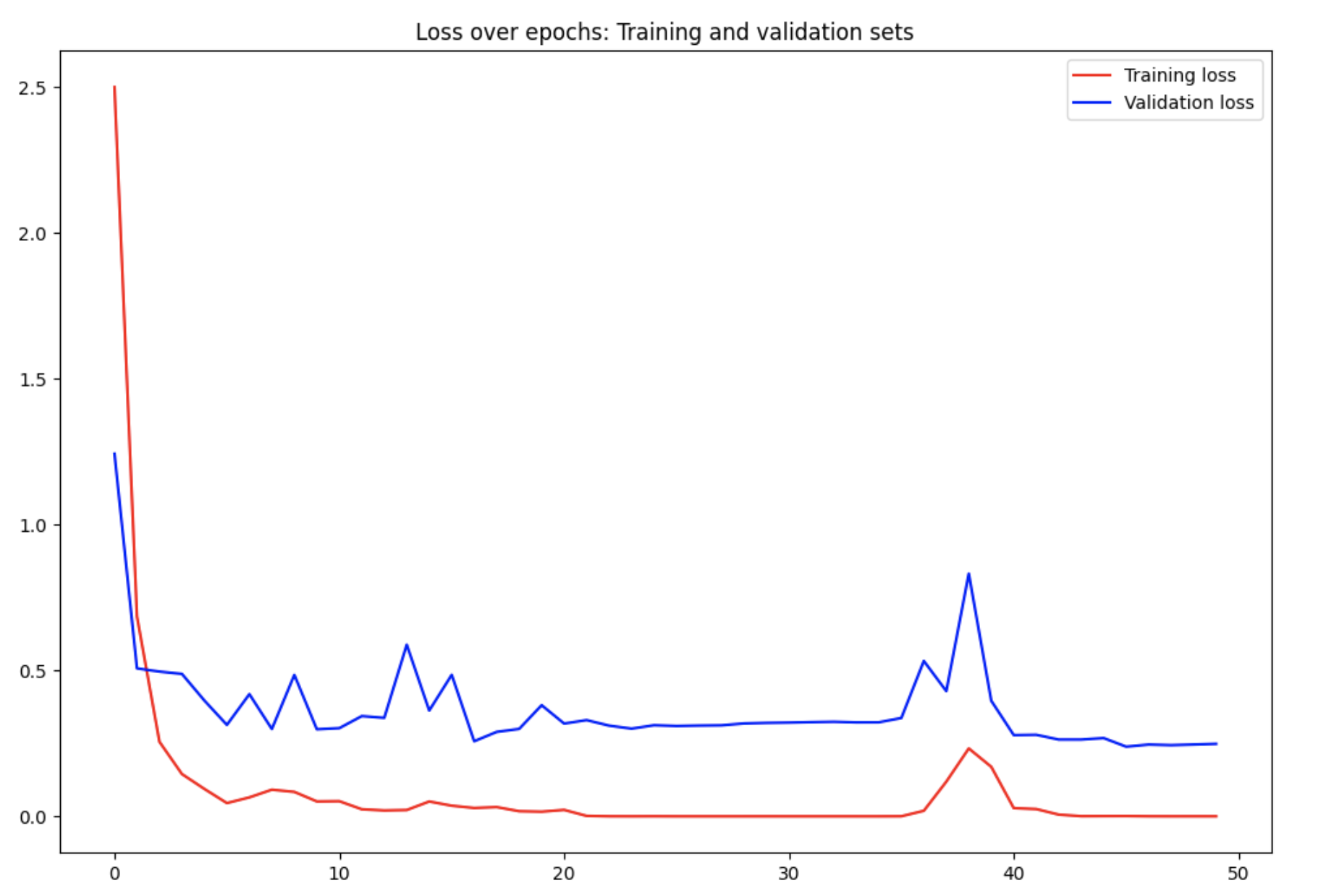
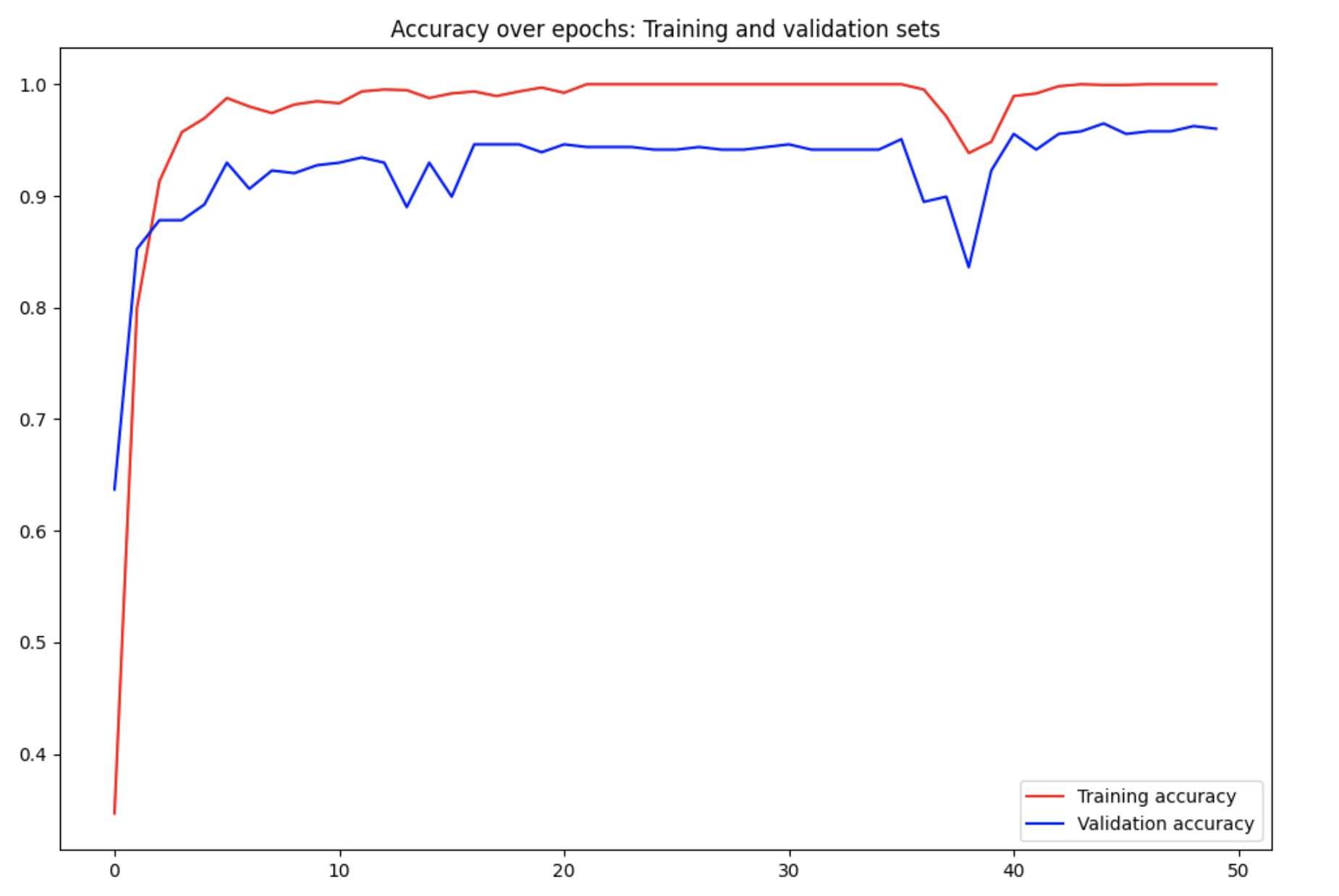
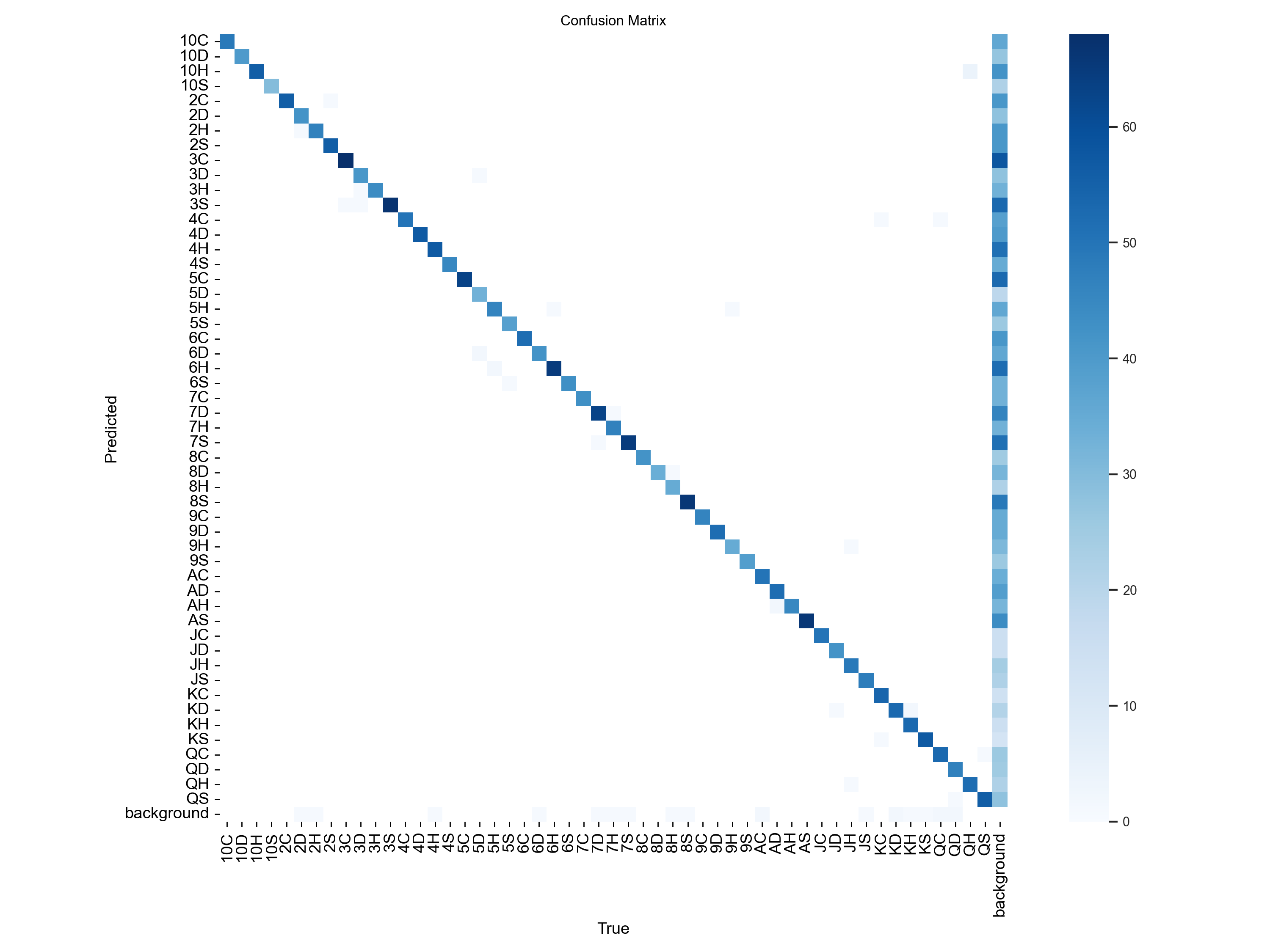
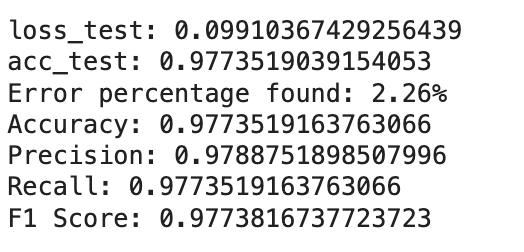
Trained with 50 epochs due to computing limitations on Google Collab free tier account, the model evaluation results indicate strong performance, with a low test loss of 0.0991 and an impressive accuracy of 97.74%, resulting in an error percentage of 2.26%. Additionally, the precision, recall, and F1 score metrics further affirm the model's robustness, showcasing well-balanced classification capabilities.
The model demonstrated excellent performance, achieving high accuracy and precision. The dropout layers contributed to regularization, preventing overfitting during training. The use of convolutional layers enables the model to learn hierarchical features, crucial for image classification tasks.
1.3. Model Prediction Results
Once the classification CNN model was trained, it was used for prediction over unseen images of cards. Here are some of the model predictions:

Clubs of 5

Clubs of Queen

Spades of 5

Diamond of King

Clubs of Ace

Clubs of 5

Incorrect !!

Diamonds of Jack
Stage 2 | Object Detection | CNNs
2.1. Overview
Once a generic model was trained to recognize playing cards, the project moved to a task of recognizing multiple cards within a single image (since a poker hand would consist of 5 cards, this was an essential step). This is object detection.
The anty was increased and involved object detection through transfer learning. Utilizing pre-trained weights from a well-known object detection base model trained on daily common objects (such as dog, cat, etc., ) YOLO Version 8.0, and fine-tuning/freezing specific layers, it was trained on project's customized dataset. This process transfers the learned configuration to project's training inputs.

2.2. Model Architecture and Training
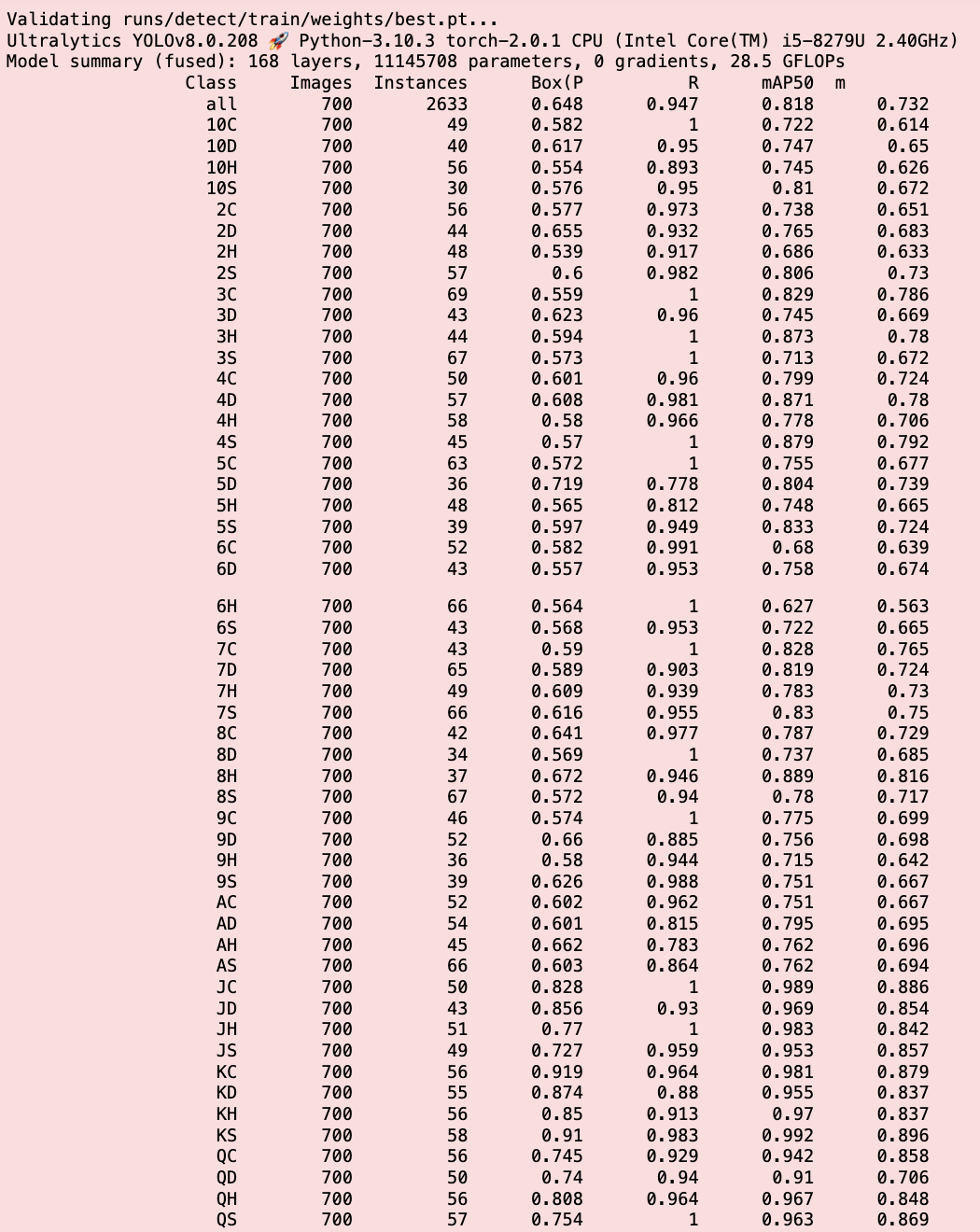
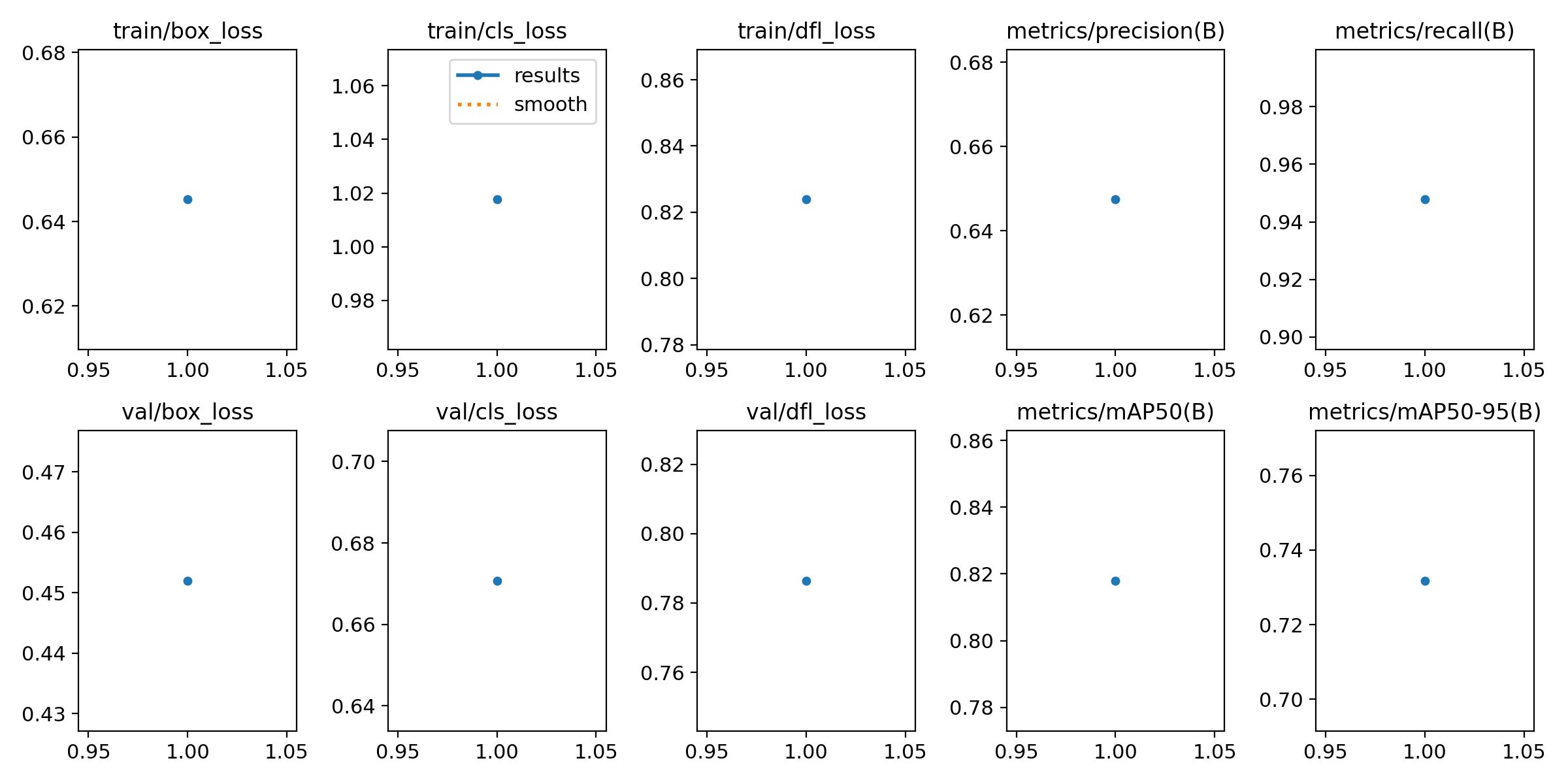
A popular object detection model YOLO version 8.0 was used for transfer learning on project's custom dataset of playing cards. Fine-tuned with 100 epochs with each image of 416 pixel size, and transferred from the base nano model in YOLO yolov8n.pt the model training process took over 11 hours to complete on a 8 core GPU machine. The model evaluation results indicated strong performance, with a low test loss of 0.642 and an impressive MAP-50 score of 82 % on average.
Fine-tuned with learned weights, the object detection CNN model was ready for prediction. Using this, the goal of detecting all the different types of cards present within a single image was achieved with good precision.

Original Image
Just the actual raw image taken from the test dataset

YOLO v8 Direct
Prediction using a pre-trained object detection model without any tuning or training

YOLO v8 Fine-tuned
Prediction using the same pre-trained object detection model but fine-tuned on the custom dataset


YOLO processes the entire image in a single forward pass, predicting bounding boxes and class probabilities simultaneously. It also divides the image into a grid, with each grid cell responsible for predicting object attributes. The architecture utilizes anchor boxes to refine bounding box predictions introducing improvements in speed and accuracy.
2.3. Model Prediction Results
Once the Object Detection model was trained, it was used for prediction over unseen images of cards. Here are some of the model predictions :

10S

9D

AC, KC, QC, JC, 10C

AC, 9S, KC, AH

9S, 10C

KH, QH, JH, 10H

AC, JH

3S, 5S, 2C, 10C
Stage 3 | User Interface | Logic
3.1. Overview
A simple user interface was created using Streamlit, Flask, Requests (API) to facilitate user access to PokerMate.
The interface features a simple design with an upload option. Users are advised to follow the input data requirements.
Once the user uploads and hits the Submit button, an API executing the model in the backend accepts the user image, classifies it into a valid card or not, detects various card labels present, and finally inferences the best poker hand.
API communicates the output to the frontend and UI displays the output with some catchy behind-the-scenes screenshots, all in real-time!
Check out the UI video demo
RESOURCES
Using Python 3.11.1, and various open sourced packages, all the files are located on my GitHub account. You may also download it by clicking the download buttons below.